Голосовой бот с искусственным интеллектом на Python

18 февраля 2022 Python
В этом руководстве разберем создание голосового бота использующего технологии нейронных сетей на языке Python. Бот может распознавать человеческий голос в реальном времени с вашего устройства, например с микрофона ноутбука, и произносить осознанные ответы, которые обрабатывает нейронная сеть.
Бот состоит из двух основных частей: это часть обрабатывающая словарь и часть с голосовым ассистентом.
Всю разработку по написанию бота вы можете вести в IDE PyCharm, скачать можно с официального сайта JetBrains.
Все необходимые библиотеки можно установить с помощью PyPI прямо в консоле PyCharm. Команды для установки вы можете найти на официальном сайте в разделе нужной библиотеки.
Проблема возникла только с библиотекой PyAudio в Windows. Помогло следующее решение:
pip install pipwin pipwin install pyaudio
Дата-сет
Дата-сет — это набор данных для анализа. В нашем случае это будет некий текстовый файл содержащий строки в виде вопрос\ответ.
Все строки текста перебираются с помощью функции for, при этом из текста удаляются все ненужные символы по маске, находящейся в переменной alphabet. Каждое значение строки раздельно заносится в массив dataset.
После обработки текста все его значения преобразуются в вектора с помощью библиотеки для машинного обучения Scikit-learn. В этом примере используется функция CountVectorizer(). Далее всем векторам присваивается класс с помощью классификатора LogisticRegression().
Когда приходит сообщение от пользователя оно так же преобразуется в вектор, и далее нейросеть пытается найти похожий вектор в датасете соответствующий какому-то вопросу, когда вектор найден, мы получим ответ.
Голосовой ассистент
Для распознавания голоса и озвучивания ответов бота, используется библиотека SpeechRecognition. Система ждет в бесконечном цикле, когда придет вопрос, в нашем случае голос с микрофона, после чего преобразует его в текст и отправляет на обработку в нейросеть. После получения текстового ответа он преобразуется в речь, запись сохраняется в папке с проектом и удаляется после воспроизведения. Вот так все просто! Для удобства все сообщения дублируются текстом в консоль.
При дефолтных настройках время ответа было достаточно долгим, иногда нужно было ждать по 15-30 сек. К тому же вопрос принимался от малейшего шума. Помогли следующие настройки:
voice_recognizer.dynamic_energy_threshold = False voice_recognizer.energy_threshold = 1000 voice_recognizer.pause_threshold = 0.5
И timeout = None, phrase_time_limit = 2 в функции listen()
После чего бот стал отвечать с минимальной задержкой.
Возможно вам подойдут другие значения. Описание этих и других настроек вы можете посмотреть все на том же сайте PyPI в разделе библиотеки SpeechRecognition. Но настройку phrase_time_limit я там почему-то не нашел, наткнулся на нее случайно в Stack Overflow.
Текст дата-сета
Это небольшой пример текста. Конечно же вопросов и ответов должно быть гораздо больше.
привет\привет как дела\всё прекрасно как дела\спасибо отлично кто ты\я бот что делаешь\с тобой разговариваю
Код Python
import speech_recognition as sr
from gtts import gTTS
import playsound
import os
import random
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
# Словарь
def clean_str(r):
r = r.lower()
r = [c for c in r if c in alphabet]
return ''.join(r)
alphabet = ' 1234567890-йцукенгшщзхъфывапролджэячсмитьбюёqwertyuiopasdfghjklzxcvbnm'
with open('dialogues.txt', encoding='utf-8') as f:
content = f.read()
blocks = content.split('\n')
dataset = []
for block in blocks:
replicas = block.split('\\')[:2]
if len(replicas) == 2:
pair = [clean_str(replicas[0]), clean_str(replicas[1])]
if pair[0] and pair[1]:
dataset.append(pair)
X_text = []
y = []
for question, answer in dataset[:10000]:
X_text.append(question)
y += [answer]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X_text)
clf = LogisticRegression()
clf.fit(X, y)
def get_generative_replica(text):
text_vector = vectorizer.transform([text]).toarray()[0]
question = clf.predict([text_vector])[0]
return question
# Голосовой ассистент
def listen():
voice_recognizer = sr.Recognizer()
voice_recognizer.dynamic_energy_threshold = False
voice_recognizer.energy_threshold = 1000
voice_recognizer.pause_threshold = 0.5
with sr.Microphone() as source:
print("Говорите 🎤")
audio = voice_recognizer.listen(source, timeout = None, phrase_time_limit = 2)
try:
voice_text = voice_recognizer.recognize_google(audio, language="ru")
print(f"Вы сказали: {voice_text}")
return voice_text
except sr.UnknownValueError:
return "Ошибка распознания"
except sr.RequestError:
return "Ошибка соединения"
def say(text):
voice = gTTS(text, lang="ru")
unique_file = "audio_" + str(random.randint(0, 10000)) + ".mp3"
voice.save(unique_file)
playsound.playsound(unique_file)
os.remove(unique_file)
print(f"Бот: {text}")
def handle_command(command):
command = command.lower()
reply = get_generative_replica(command)
say(reply)
def stop():
say("Пока")
def start():
print(f"Запуск бота...")
while True:
command = listen()
handle_command(command)
try:
start()
except KeyboardInterrupt:
stop()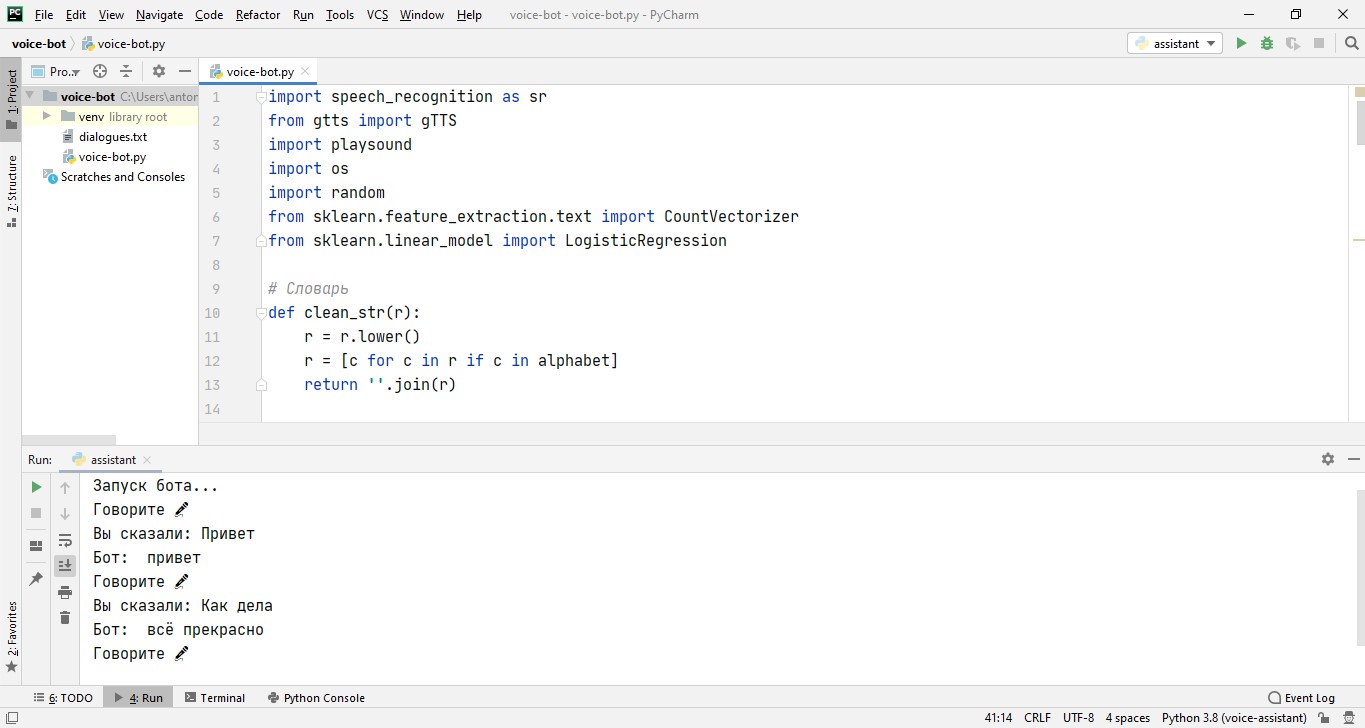
Пример одного из самых популярных голосовых помощников — это яндекс алиса.

Из видео вы узнаете, что такое нейронные сети, и как они используются. Всего лишь за 30 минут вы узнаете минимально необходимую теорию, а так же сможете написать свою первую многослойную нейронную сеть самостоятельно (она займет не более 50 строк кода!). Читать далее

Это первый урок из цикла небольших статей для тех, кто только начинает изучать язык программирования Python или программирование в целом. Как известно Python язык с низким порогом вхождения, поэтому он подойдет и как первый язык для начала изучения программирования. На Читать далее
После того, как вы скачали и установили интерпретатор Python, пришло время создать вашу первую программу. По традиции это будет "Hello Word". Но открывать мы её будем не просто в командной строке, а как страницу в браузере. 1. Запустите веб-сервер Веб-сервер Читать далее

На прошлом уроке мы с вами создали простое веб-приложение печатающее "Hello World". Как я и обещал в этом уроке мы уже создадим простую нейросеть на языке Python, да да и это не шутка, такой вот это простой язык. Для Python Читать далее

В этом руководстве разберем создание голосового бота использующего технологии нейронных сетей на языке Python. Бот может распознавать человеческий голос в реальном времени с вашего устройства, например с микрофона ноутбука, и произносить осознанные ответы, которые обрабатывает нейронная сеть. Бот состоит из Читать далее
где найти dialogues.txt ?????????????
Создаешь его сам и вписываешь туда:
привет\привет
как дела\всё прекрасно
как дела\спасибо отлично
кто ты\я бот
что делаешь\с тобой разговариваю
Cпасибо большущее за исходник!!! С гитхаба разные пробовал, но этот с первого раза заработал со звуком.
Привожу пример своего диалога (звук пока отключил):
hello
hello
how are you?
i’m fine
what about weather?
the weather is nice
do you like weather
not very i prefer a dogs
have you a cat?
i have one dog
do You like a movies
not very i prefer a dogs
my dog’s name is Tobi
my dog’s name is Suzy
what do You like?
i like to drink a cola
bye
bye
Обратите внимание, что нет ни одной раздражающей ошибки!!!
русский вариант:
привет
привет
как дела?
прекрасно
как погода?
замечательная погода
тебе нравится погода?
замечательная погода
тебе нравятся погоды?
не очень я предпочитаю собак
тебе нравится смотреть фильмы?
не очень я предпочитаю собак
мою собаку зовут Тоби
мою собаку зовут Сюзи
что тебе нравится?
не очень я предпочитаю собак
что ты любишь?
я предпочитаю колу
пока
пока
Данный подход основан на выборе готовой, шаблонной фразы и этот подход имеет право на существование, так как люди в 80% используют шаблоны, как бездумно, так и намеренно (для лучшего понимания)!
что делать если, на другие вопросы которое не записанны в txt он отвечает привет?
Как сделать так, чтоб при слове «пока» программа сама останавливалась?
помоги такая ошибка
Error 263 for command:
open audio_6379.mp3
Указанное устройство не открыто или не опознается интерфейсом MCI.
Error 263 for command:
close audio_6379.mp3
Указанное устройство не открыто или не опознается интерфейсом MCI.
Failed to close the file: audio_6379.mp3
Traceback (most recent call last):
File «C:/Users/dexfr/Desktop/da3.py», line 73, in
start()
File «C:/Users/dexfr/Desktop/da3.py», line 71, in start
handle_command(command)
File «C:/Users/dexfr/Desktop/da3.py», line 64, in handle_command
say(reply)
File «C:/Users/dexfr/Desktop/da3.py», line 58, in say
playsound.playsound(unique_file)
File «C:\Users\dexfr\AppData\Local\Programs\Python\Python310\lib\site-packages\playsound.py», line 72, in _playsoundWin
winCommand(u’open {}’.format(sound))
File «C:\Users\dexfr\AppData\Local\Programs\Python\Python310\lib\site-packages\playsound.py», line 64, in winCommand
raise PlaysoundException(exceptionMessage)
playsound.PlaysoundException:
Error 263 for command:
open audio_6379.mp3
Указанное устройство не открыто или не опознается интерфейсом MCI.
Подскажите пожалуйста, что делать с ошибкой:
line 18, in
with open(‘dialogues.txt’, encoding=’utf-8′) as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘dialogues.txt’
создай в папке с питоном где сохраняеш исходник текстовый документ dialogues.txt и внеси в него список команд.
Пример:
привет\привет
как дела\всё прекрасно
как дела\спасибо отлично
кто ты\я бот
что делаешь\с тобой разговариваю
Команды можно добовлять
Подскажите пожалуйста, что делать с ошибкой: Как исправить?
Traceback (most recent call last):
File «C:/Users/Shokudo/PycharmProjects/pythonProject3/main.py», line 15, in
content = f.read()
File «C:\Users\Shokudo\AppData\Local\Programs\Python\Python37\lib\codecs.py», line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xef in position 0: invalid continuation byte
Process finished with exit code 1
Вопрос — как подружить с sip телефонией
В терминале пишет:
>>> & C:/Users/Даня/AppData/Local/Programs/Python/Python311/python.exe «e:/Torrent Games/1assistvoice.py»
File «», line 1
& C:/Users/Даня/AppData/Local/Programs/Python/Python311/python.exe «e:/Torrent Games/1assistvoice.py»
^
SyntaxError: invalid syntax
>>>
Что делать? Что не так, напишите подробно, пожалуйста
Если ошибка с аудиофайлом, как у Дениса, дело в самом модуле. Нужна версия 1.2.2.
Нужно установить библиотеки:
pip uninstall playsound
pip install playsound==1.2.2
Такой же вопрос как у Егора
что делать если, на другие вопросы, которое не записанны в txt, И ДАЖЕ НА МОЛЧАНИЕ он отвечает привет?
Подскажите, а он тоже говорит?
что делать подскажите пожалуйста 3 день учу питон
File «C:\Users\genri\AppData\Local\Programs\Python\Python312\Lib\site-packages\speech_recognition\__init__.py», line 111, in get_pyaudio
from distutils.version import LooseVersion
ModuleNotFoundError: No module named ‘distutils’
PS C:\Users\genri\goose>
Я хочу создать компаньона